Building an AI assistant for computational modelling with NeuroML
- #LLM, #RAG, #NeuroML, #Neuroscience, #Computational neuroscience, #Computational modelling, #LangChain, #LangGraph, #Agentic AI, #Tools, #MCP, #Ollama, #Python, #Fedora
Brain models are hard to build
While experiments remain the primary method by which we neuroscientists gather information on the brain, we still rely on theory and models to combine experimental observations into unified theories. Models allow us to modify and record from all components, and they allow us to simulate various conditions---all of which is quite hard to do in experiments.
Researchers model the brain at multiple levels of detail depending on what it is they are looking to study. Biologically detailed models, where we include all the biological mechanisms that we know of---detailed neuronal morphologies and ionic conductances---are important for us to understand the mechanisms underlying emergent behaviours.
These detailed models are complex and difficult to work with. NeuroML, a standard and software ecosystem for computational modelling in Neuroscience, aims to help by making models easier to work with. The standard provides ready-to-use model components and models can be validated before they are simulated. NeuroML is also simulator independent, which allows researchers to create a model and run it using a supported simulation engine of choice.
In spite of NeuroML and other community developed tools, a bottleneck remains. In addition to the biology and biophysics, to build and run models, one also needs to know modelling/simulation and related software development practices. This is a lot, presents quite a steep learning curve and makes modelling less accessible to researchers.
LLM based assistants provide a possible solution
LLMs allow users to interact with complex systems using natural language by mapping user queries to relevant concepts and context. This makes it possible to use LLMs as an interface layer where researchers can continue to use their own terminology and domain-specific language, rather than first learning a new tool's vocabulary. They can ask general questions, interactively explore concepts through a chat interface, and slowly build up their knowledge.
We are currently leveraging LLMs in two ways.
RAG
The first way we are using LLMs is to make it easier for people to query information about NeuroML.
As a first implementation, we queried standard LLMs (ChatGPT/Gemini/Claude) for information. While this seemingly worked well and the responses sounded correct, given that LLMs have a tendency to hallucinate, there was no way to ensure that the generated responses were factually correct.
This is a well known issue with LLMs, and the current industry solution for building knowledge systems using LLMs with correctness in mind is the RAG system. In a RAG system, instead of the LLM answering a user query using its own trained data, the LLM is provided with curated data from an information store and asked to generate a response strictly based on it. This helps to limit the response to known correct data, and greatly improves the quality of the responses. RAGs can still generate errors, though, since their responses are only as good as the underlying sources and prompts used, but they perform better than off-the-shelf LLMs.
For NeuroML we use the following sources of verified information:
- the documentation from https://docs.neuroml.org
- NeuroML publications
- other sources, such as well validated models from our Open Source Brain platform
I have spent the past couple of months creating a RAG for NeuroML. The code lives here on GitHub and a test deployment is here on HuggingFace. It works well, so we consider it stable and ready for use.
Here is a quick demo screen cast:
We haven't dedicated too many resources to the HuggingFace instance, though, as it's meant to be a demo only. If you do wish to use it extensively, a more robust way is to run it locally on your computer. If you have the hardware, you can use it completely offline by using locally installed models via Ollama (as I do on my Fedora Linux installation). If not, you can also use any of the standard models, either directly, or via other providers like HuggingFace.
The package can be installed using pip, and more instructions on installation and configuration is included in the package Readme.
Please do use it and provide feedback on how we can improve it.
Implementation notes (for those interested)
The RAG system is implemented as a Python package using LangChain/LangGraph. The "LangGraph" for the system is shown below. We use the LLM to generate a search query for the retrieval step, and we also include an evaluator node that checks if the generated response is good enough---whether it uses the context, answers the query, and is complete. If not, we iterate to either get more data from the store, to regenerate a better response, or to generate a new query.
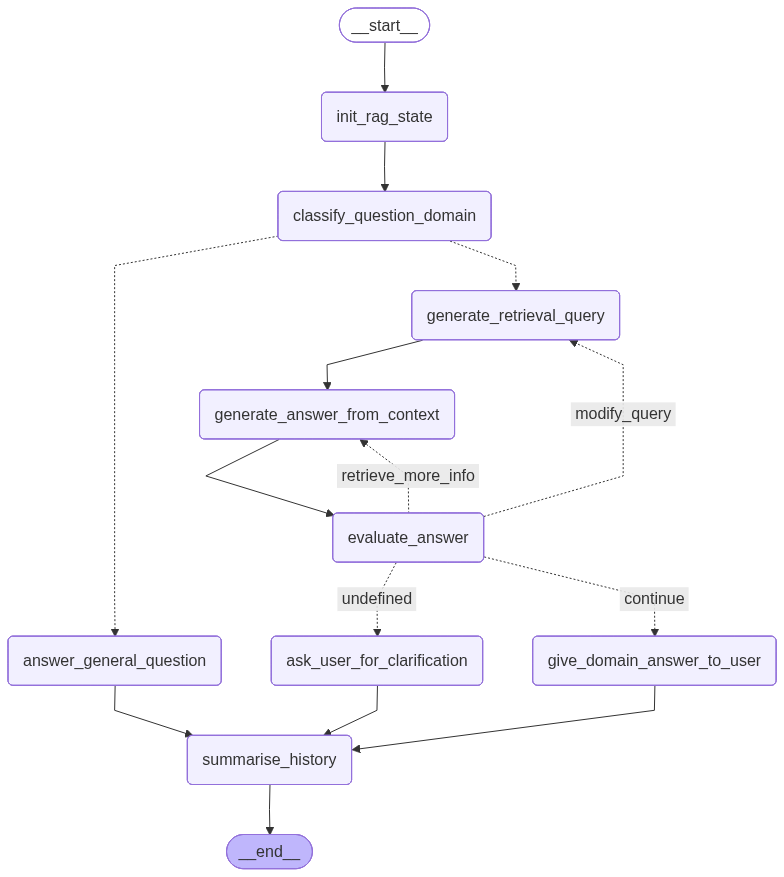
The RAG system exposes a REST API (using FastAPI) and can be used via any clients. A couple are provided---a command line interface and a Streamlit based web interface (shown in the demo video).
The RAG system is designed to be generic. Using configuration files, one can specify what domains the system is to answer questions about, and provide vector stores for each domain. So, you can also use it for your own, non-NeuroML, purposes.
Model generation and simulation
The second way in which we are looking to accelerate modelling using LLMs is by using them to help researchers build and simulate models.
Unfortunately, off-the-shelf LLMs don't do well when generating NeuroML code, even though they are consistently getting better at generating standard programming language code. In my testing, they tended to write "correct Python", but mixed up lots of different libraries with NeuroML APIs. This is likely because there isn't so much NeuroML Python code out there for LLMs to "learn" from during their training.
One option is for us to fine tune a model with NeuroML examples, but this is quite an undertaking. We currently don't have access to the infrastructure required to do this, and even if we did, we will still need to generate synthetic NeuroML examples for the fine-tuning. Finally, we would need to publish/host/deploy the model for the community to use.
An alternative, with function/tool calls becoming the norm in LLMs, is to set up a LLM based agentic code generation workflow.
Unlike a free-flowing general-purpose programming language like Python, NeuroML has a formally defined schema which models can be validated against. Each model component fits in at a particular place, and each parameter is clearly defined in terms of its units and significance. NeuroML provides multiple levels of validation that give the user specific, detailed feedback when a model component is found to be invalid. Further, the NeuroML libraries already include functions to validate models, read and write them, and to simulate them using different simulation engines.
These features lend themselves nicely to a workflow in which an LLM iteratively generates small NeuroML components, validates them, and refines them based on structured feedback. This is currently a work in progress in a separate package.
I plan to write a follow up post on this once I have a working prototype.
While being mindful of the hype around LLMs/AI, we do believe that these tools can accelerate science by removing/reducing some common accessibility barriers. They're certainly worth experimenting with, and I am hopeful that the modelling/simulation pipeline will help experimentalists that would like to integrate modelling in their work do so, completing the neuroscience research loop.
Comments